Năm 2006, Clive Humby - nhà toán học và kiến trúc người Anh làm việc cho Câu lạc bộ thẻ Tesco đã lần đầu tiên đưa ra quan điểm: “Dữ liệu là nguồn dầu mỏ mới. Dữ liệu rất giá trị, nhưng nếu không được xử lý thì gần như không sử dụng được. Giống như dầu mỏ cần được chuyển hóa thành khí gas, nhựa plastic, xăng... để tạo ra các thực thể có giá trị, đem lại lợi nhuận cho tổ chức; dữ liệu cần được chia nhỏ, phân tích để tạo ra giá trị”.
Dữ liệu có ở xung quanh và đang từng giờ thay đổi cuộc sống của chúng ta. Lấy một ví dụ đơn giản, nền tảng chia sẻ video Youtube của Google trả tiền cho các Youtuber tạo ra nội dung chia sẻ dựa trên lượt view. Điều này đặt ra câu hỏi: Chi phí nào để Youtube trả tiền cho các Youtuber? Thực tế, Youtube chèn các quảng cáo vào trong nội dung video. Điều này đồng nghĩa với việc, khi người dùng xem video là sẽ phải xem các nội dung quảng cáo. Việc nội dung quảng cáo phản ánh sản phẩm nào sẽ phụ thuộc hoàn toàn vào việc thu thập, phân tích hành vi xem video của người dùng. Nói đến đây, chắc hẳn độc giả đã thấy tại sao dữ liệu lại là "nguồn dầu mỏ mới".
Nếu bạn vẫn chưa thực sự bị thuyết phục rằng dữ liệu là “nguồn dầu mỏ mới”, thì hãy đọc cuốn sách “Dữ liệu lớn – Big Data” của các tác giả Viktor Mayer-Schonberger và Kenneth Cukier. Ngay từ chương đầu tiên của cuốn sách đã mô tả việc các nhà khoa học dữ liệu của Google chỉ ra phương pháp làm sao để biết mức độ di chuyển và phạm vi của một dịch cúm. Dựa trên việc nghiên cứu hàng tỉ câu hỏi trên trang tìm kiếm của Google từ khắp nơi trên thế giới, thông qua các từ khóa tìm kiếm liên quan đến dịch cúm. Từ đó, các nhà khoa học dữ liệu Google có thể bản đồ hóa khu vực có các từ khóa tìm kiếm liên quan để biết mức độ phát triển và phạm vi của dịch cúm. Việc thu thập, lưu trữ, xử lý hàng tỉ câu hỏi từ khắp nơi trên thế giới không phải là công việc dễ dàng. Tuy nhiên, kết quả mà nó đem lại có giá trị to lớn vào thời điểm dịch cúm xảy ra.
Dữ liệu bị phát tán từ đâu?
Phần lớn chúng ta đều nghĩ rằng dữ liệu của các tổ chức tài chính ngân hàng bị rò rỉ là do hacker thực hiện các cuộc tấn công vào hệ thống cơ sở dữ liệu của ngân hàng để truy cập trái phép dữ liệu nhạy cảm của khách hàng. Tuy nhiên, đó chỉ là một phần của vấn đề, có rất nhiều trường hợp dữ liệu bị phát tán từ chính những người trong tổ chức, một cách vô tình hay cố ý.
Điển hình, năm 2013 một cán bộ tín dụng của một ngân hàng thương mại cổ phần (TMCP) đã mượn tài khoản của đồng nghiệp để truy cập trái phép và sao lưu dữ liệu của hơn 1.000 khách hàng có số dư tiết kiệm trên 500 triệu VNĐ. Dữ liệu này được sử dụng cho mục đích cá nhân và bán cho các nhân viên của ngân hàng khác. Khi bị phát hiện, cán bộ này đã bị sa thải và phải chịu án tù treo 2 năm. Tuy nhiên, chưa có ai kiểm chứng được dữ liệu đã được bán cho những ai và bao nhiêu lần?
Bên cạnh đó, hình thức công khai bán dữ liệu khách hàng cũng rất phổ biến trên Internet. Lợi dụng tính ẩn danh của google, một website đã công khai rao bán dữ liệu của hơn 4 triệu khách hàng ở mọi lĩnh vực, trong đó có lĩnh vực ngân hàng. Một điều ngạc nhiên là dữ liệu được bán có thể phân loại như khách hàng có dùng thẻ và loại thẻ. Những dữ liệu này chỉ có được khi nguồn phát tán từ chính nội bộ của ngân hàng đó.

Hình 1: Thông tin khách hàng sử dụng thẻ của một ngân hàng TMCP tại Hồ Chí Minh được rao bán
Vậy các ngân hàng quản lý dữ liệu của mình thế nào? Vấn đề này được giải quyết trên hai khía cạnh: nhận thức về giá trị dữ liệu của ngân hàng và hiện trạng quản lý dữ liệu tại các ngân hàng.
Hiện trạng bảo mật, chia sẻ dữ liệu nội bộ trong ngân hàng
Nhận thức về giá trị dữ liệu của ngân hàng
Năm 2018, một khảo sát về mức độ trưởng thành quản trị dữ liệu trong phạm vi nhỏ đã được thực hiện khi triển khai Khung Quản trị dữ liệu tại Việt Nam. Nội dung khảo sát được xây dựng dựa trên hai mô hình nổi tiếng trên thế giới: Mô hình đánh giá năng lực quản lý dữ liệu (Data Management Capabilities Assessment Model - DCAM) do EDM Council phát triển và Đánh giá trưởng thành quản lý dữ liệu (Data Management Maturity Assessment - DMMA) do DAMA International.
Mô hình trưởng thành quản trị dữ liệu được sử dụng trong khảo sát bao gồm 6 mức trưởng thành (Chưa bắt đầu, Có ý tưởng, Đang phát triển, Đã xác định, Hoàn thành và Tối ưu) xét trên 3 khía cạnh (Quy trình, mức độ gắn kết và tổ chức). Kết quả khảo sát cho thấy, các ngân hàng Việt Nam đang ở mức đầu tiên trong 6 mức trưởng thành quản trị dữ liệu. Điều này cho thấy các ngân hàng Việt Nam chưa thực sự chú trọng vào việc quản trị dữ liệu và chưa có mức đầu tư xứng đáng vào công tác này. Tại thị trường Mỹ hay các nước phát triển ở Châu Âu, các ngân hàng đang xếp ở mức 4 (Đã xác định) và đang tiến tới mức 5 (Hoàn thành). Còn khối thị trường đang phát triển ở Châu Á và Châu Phi, thì các ngân hàng đang ở mức 3 là mức Đang phát triển. Như vậy, có một khoảng cách lớn giữa thị trường Việt Nam và các nước trong khu vực và trên thế giới.
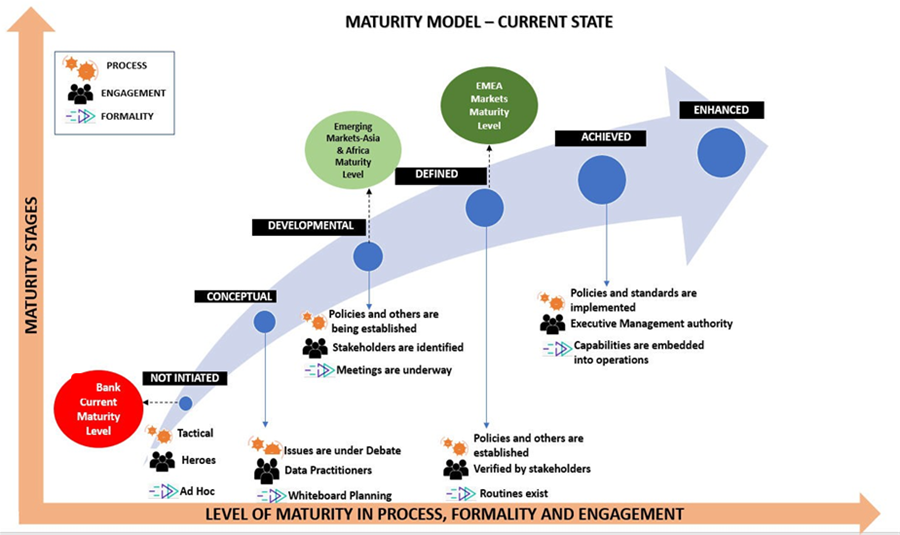
Hình 2: Mức độ trưởng thành quản trị dữ liệu
Thực tế, thuật ngữ “Quản trị dữ liệu” mới thực sự được các ngân hàng quan tâm từ năm 2014. Hiện tại, việc triển khai quản trị dữ liệu tại các ngân hàng Việt Nam còn rất hạn chế, thậm chí còn rất nhiều các ngân hàng mới có ý tưởng manh nha về vấn đề này. Một tín hiệu tích cực là một số lãnh đạo ngân hàng đã nhìn nhận được tầm quan trọng của dữ liệu cho định hướng kinh doanh của ngân hàng. Tuy nhiên, thông điệp này vẫn chưa được truyền tải tới các cán bộ nhân viên của ngân hàng, những người đang hàng ngày tiếp xúc với dữ liệu.
Về mặt tổ chức đơn vị quản trị dữ liệu, phần lớn các ngân hàng đang sử dụng mô hình phân tán, nghĩa là tồn tại nhiều đơn vị thu thập và khai thác dữ liệu độc lập.
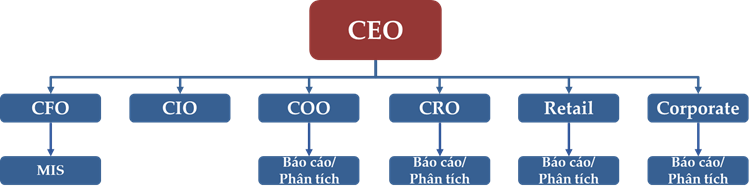
Hình 3: Mô hình thu thập và khai thác dữ liệu phân tán tại ngân hàng
Với mô hình phân tán này, mỗi khối nghiệp vụ sẽ có một phòng, ban thu thập và xử lý dữ liệu độc lập, việc này dẫn đến dữ liệu sẽ bị quản lý phân tán, các đơn vị khai thác cùng một loại dữ liệu sẽ không tối ưu được nguồn lực, dễ dẫn đến thông tin cung cấp cho các cấp lãnh đạo không đồng nhất làm cho việc ra quyết định kinh doanh gặp nhiều khó khăn. Với mô hình phân tán như vậy, việc chia sẻ hay truy cập vào dữ liệu không phù hợp với vị trí công việc rất dễ xảy ra và gây khó khăn trong việc kiểm soát. Đây là nguyên nhân cho việc dữ liệu khách hàng bị phát tán ra bên ngoài mà không kiểm soát.
Hiện trạng quản lý dữ liệu tại các ngân hàng
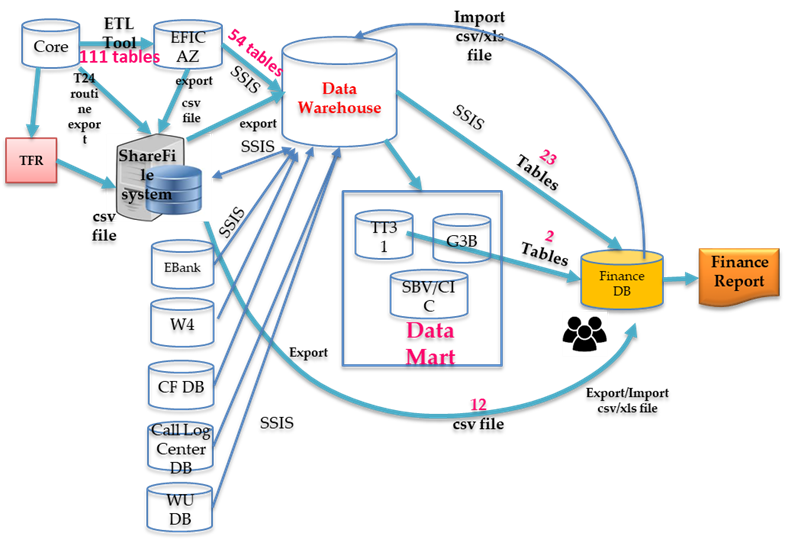
Hình 4: Hiện trạng quản lý dữ liệu trên hệ thống
Việc quản lý dữ liệu ngân hàng hiện nay cơ bản chưa được thống nhất. Từ năm 2009 đến nay, phần lớn các ngân hàng đều đã triển khai hệ thống Kho Dữ liệu (Data Warehouse). Tuy nhiên, giá trị đem lại của Kho dữ liệu này rất khó kiểm chứng, khi mà Kho dữ liệu này không phải là duy nhất. Các ngân hàng đang tồn tại song song nhiều kho dữ liệu khác nhau, bản thân các đơn vị nghiệp vụ cũng có kho dữ liệu lưu trữ của riêng mình và gần như không sử dụng kho dữ liệu chung của toàn ngân hàng.
Một điểm đáng lo khác là luồng dữ liệu luân chuyển giữa các hệ thống hiện tại chưa được quy hoạch và cũng chưa được ghi nhận trên tài liệu, dẫn đến rất nhiều khó khăn cho việc quản lý và khai thác dữ liệu. Việc tồn tại song song nhiều kho dữ liệu, luồng dữ liệu chưa được chuẩn hóa và ghi nhận trên tài liệu là một trong những nguyên nhân dẫn đến nguy cơ rò rỉ thông tin.
Có sự khác biệt không nhỏ trong mô hình kiến trúc hiện tại của các ngân hàng (Hình 4) và mô hình kiến trúc dữ liệu đề xuất (Hình 5).
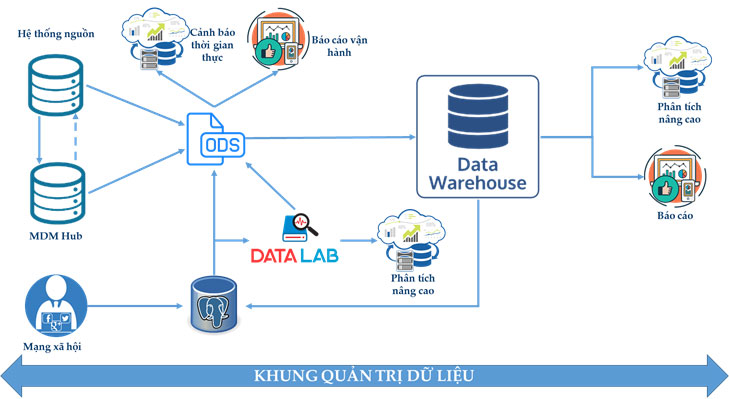
Hình 5: Mô hình kiến trúc dữ liệu đề xuất
Như vậy, ở cả hai góc độ là nhận thức về giá trị của dữ liệu và hiện trạng quản lý dữ liệu của ngân hàng đều tồn tại những vấn đề cần phải khắc phục. Làm sao để ngân hàng cải thiện việc quản trị dữ liệu của mình, qua đó nâng cao bảo mật thông tin? Câu trả lời này sẽ được giải đáp tại phần tiếp theo của bài báo. Kính mời quý độc giả đón đọc.
Nguyễn Minh Đức - Ngân hàng TMCP Quân đội (MB Bank)

14:00 | 29/11/2019

14:00 | 29/11/2019

10:00 | 12/01/2021

16:00 | 03/05/2021

14:00 | 07/07/2021

08:00 | 01/09/2021

16:00 | 12/12/2019

10:00 | 22/03/2024
Với sự tương tác kinh tế, xã hội và văn hóa ngày càng diễn ra phổ biến trên Internet, nhu cầu ngày càng tăng trong vài thập kỷ qua nhằm bắt chước sự ngẫu nhiên của thế giới tự nhiên và tạo ra các hệ thống kỹ thuật số để tạo ra các kết quả không thể đoán trước. Các trường hợp sử dụng cho tính không thể đoán trước này bao gồm đưa vào sự khan hiếm nhân tạo, xây dựng các cơ chế bảo mật mạnh mẽ hơn và tạo điều kiện cho các quy trình ra quyết định trung lập đáng tin cậy. Trong bài viết này, tác giả sẽ phân tích tính ngẫu nhiên, tìm hiểu về các loại ngẫu nhiên và vai trò quan trọng của sự ngẫu nhiên đối với Blockchain và hệ sinh thái Web3.

10:00 | 30/01/2023
Blockchain (chuỗi khối) là một cơ sở dữ liệu phân tán với các đặc trưng như tính phi tập trung, tính minh bạch, tính bảo mật dữ liệu, không thể làm giả. Vì vậy công nghệ Blockchain đã và đang được ứng dụng vào rất nhiều lĩnh vực trong đời sống như Y tế, Nông nghiệp, Giáo dục, Tài chính ngân hàng,... Bài báo này sẽ giới thiệu về công nghệ Blockchain và đề xuất một mô hình sử dụng nền tảng Hyperledger Fabric để lưu trữ dữ liệu sinh viên như điểm số, đề tài, văn bằng, chứng chỉ trong suốt quá trình học. Việc sử dụng công nghệ Blockchain để quản lý dữ liệu sinh viên nhằm đảm bảo công khai minh bạch cho sinh viên, giảng viên, các khoa, phòng chức năng. Đồng thời giúp xác thực, tra cứu các thông tin về văn bằng, chứng chỉ góp phần hạn chế việc sử dụng văn bằng, chứng chỉ giả hiện nay.

08:00 | 03/01/2023
Các thiết bị Smartphone ngày nay đang phải đối mặt với nhiều mối đe dọa khác nhau, bất kể đó là hệ điều hành Android hay iOS. Thông qua các liên kết độc hại được gửi qua mạng xã hội, đến những chương trình có khả năng theo dõi, xâm phạm các ứng dụng hoặc triển khai mã độc tống tiền trên thiết bị của người dùng. Bài báo sẽ giới thiệu đến độc giả các mối đe dọa phổ biến nhắm vào thiết bị Smartphone giúp người dùng có thể chủ động phòng tránh.

16:00 | 30/11/2022
Trong phần I của bài báo, nhóm tác giả sẽ giới thiệu cách thức xây dựng bộ dữ liệu IDS2021-WEB trích xuất từ bộ dữ liệu gốc CSE-CIC-IDS2018. Theo đó, các bước tiền xử lý dữ liệu được thực hiện từ bộ dữ liệu gốc như lọc các dữ liệu trùng, các dữ liệu dư thừa, dữ liệu không mang giá trị. Kết quả thu được là một bộ dữ liệu mới có kích thước nhỏ hơn và số lượng thuộc tính ít hơn. Đồng thời, đề xuất mô hình sử dụng bộ dữ liệu về xây dựng hệ thống phát hiện tấn công ứng dụng website.
08:00 | 11/01/2024 | Chính sách - Chiến lược

09:00 | 10/01/2024 | Giải pháp khác

09:00 | 05/01/2024|Chính sách - Chiến lược
09:00 | 05/01/2024|An ninh – Quốc Phòng

Có một số phương pháp để xác định mức độ an toàn của các hệ mật sử dụng độ dài khóa mã (key length) tham chiếu làm thông số để đo độ mật trong cả hệ mật đối xứng và bất đối xứng. Trong bài báo này, nhóm tác giả tổng hợp một số phương pháp xác định độ an toàn của hệ mật khóa công khai RSA, dựa trên cơ sở các thuật toán thực thi phân tích thừa số của số nguyên modulo N liên quan đến sức mạnh tính toán (mật độ tích hợp Transistor theo luật Moore và năng lực tính toán lượng tử) cần thiết để phá vỡ một bản mã (các số nguyên lớn) được mã hóa bởi khóa riêng có độ dài bit cho trước. Mối quan hệ này giúp ước lượng độ an toàn của hệ mật RSA theo độ dài khóa mã trước các viễn cảnh tấn công khác nhau.
08:00 | 04/04/2024

Theo báo cáo năm 2022 về những mối đe doạ mạng của SonicWall, trong năm 2021, thế giới có tổng cộng 623,3 triệu cuộc tấn công ransomware, tương đương với trung bình có 19 cuộc tấn công mỗi giây. Điều này cho thấy một nhu cầu cấp thiết là các tổ chức cần tăng cường khả năng an ninh mạng của mình. Như việc gần đây, các cuộc tấn công mã độc tống tiền (ransomware) liên tục xảy ra. Do đó, các tổ chức, doanh nghiệp cần quan tâm hơn đến phương án khôi phục sau khi bị tấn công.
19:00 | 30/04/2024


















