Phát tán thư rác là hành vi gửi thư điện tử mà người nhận không mong muốn, thường với nội dung quảng cáo, được gửi hàng loạt với số lượng lớn tới một tập hợp người nhận không phân biệt. Kẻ phát tán thư rác có thể lấy địa chỉ thư điện tử từ các trang web, phòng chat, tập dữ liệu cá nhân bị rò rỉ,…
Thư rác gây ra nhiều phiền toái và thiệt hại, bao gồm, ngăn người dùng sử dụng tối ưu thời gian, dung lượng lưu trữ và băng thông mạng. Một số lượng lớn thư rác truyền trong mạng máy tính có thể phá hủy không gian nhớ của máy chủ thư điện tử, băng thông đường truyền, tài nguyên tính toán và thời gian sử dụng của thiết bị người dùng.
Theo thống kê từ Công ty dữ liệu và thị trường Statista (Đức - Công ty nổi tiếng về số liệu với khoảng 1.000.000 thống kê về hơn 80.000 chủ đề từ hơn 22.500 nguồn và 170 ngành khác nhau trên toàn thế giới), số lượng thư rác đã lên đến 92,6% trong tổng số lượng thư điện tử được gửi đi vào năm 2008, sau đó có xu hướng giảm dần trong những năm gần đây do sự phát triển của các hệ thống chống thư rác. Vào năm 2019, số liệu này đã giảm còn 28,5%.
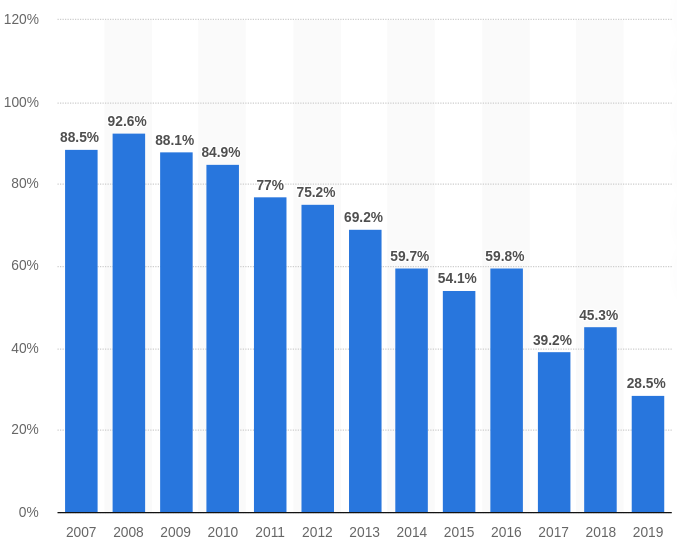
Hình 1. Thống kê tỷ lệ thư rác từ năm 2007 đến năm 2019 (Statista)
Tuy nhiên, điểm yếu của bộ lọc thư rác là đôi khi thư hợp pháp có thể bị đánh dấu là thư rác, từ đó có thể bị từ chối hoặc loại bỏ. Chính vì vậy, mục đích của bài báo là nghiên cứu ứng dụng của học máy đối với lọc thư rác, bằng cách đưa ra một bức tranh tổng quan về thư rác, liệt kê những giải pháp đã có, chỉ ra nhu cầu của học máy trong việc lọc thư rác, trình bày việc áp dụng học máy đối với nhiệm vụ này thông qua 2 thuật toán phổ biến là Naïve Bayes và SVM.
Bộ lọc thư rác hoạt động bằng cách phân tích thư trước khi được đưa vào hộp thư đến của người dùng nhằm kiểm tra xem có phải thư rác hay không. Bộ lọc này phân tích nội dung, địa chỉ gửi thư, đầu thư (header), các tệp đính kèm, ngôn ngữ và các dấu hiệu khả nghi khác.
Có nhiều phương pháp phân loại thư rác, trong đó quy trình lọc thư rác tiêu chuẩn bao gồm những thành phần sau [2]:
- Lọc nội dung (content filter): phân loại thư rác dựa trên nội dung thư bằng các phương pháp như: thống kê truyền thống, học máy...;
- Lọc đầu thư (header filter): trích xuất thông tin từ đầu thư để lọc;
- Lọc theo danh sách đen (blacklist filter): xác định thư rác và địa chỉ thư gửi thư rác từ danh sách đen;
- Lọc dựa trên quy luật (rule-based filter): nhận diện người gửi cụ thể qua đầu thư sử dụng các tiêu chí do người dùng đặt ra;
- Lọc bằng cấp quyền (permission filter): gửi thư bằng cách có sự đồng ý của người nhận từ trước;
- Lọc nhờ xác thực bằng cách trả lời (challenge-response filter): kiểm tra thư được gửi tự động hay do người trực tiếp gửi (thông thường thư rác đều được tạo và gửi tự động thông qua phần mềm) qua việc người gửi trả lời để xác thực.
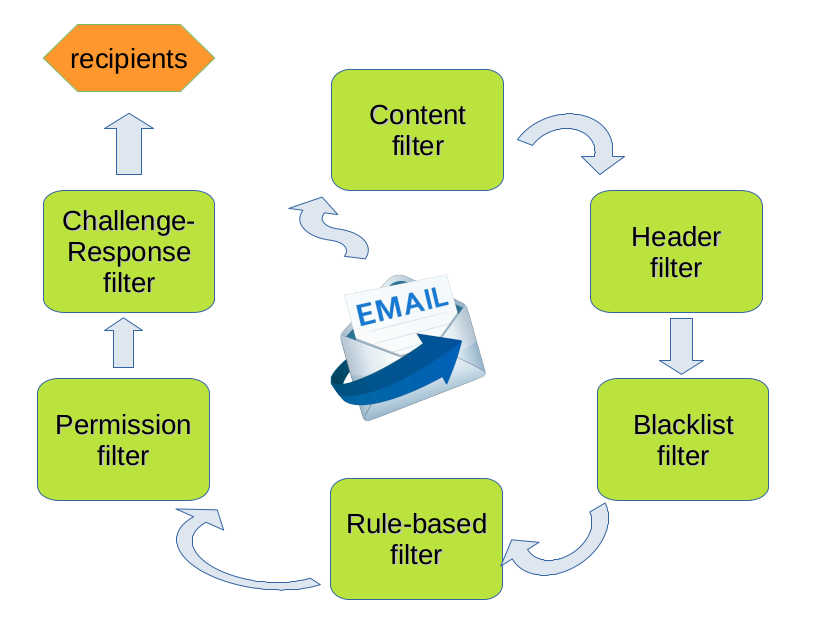
Hình 2. Quy trình lọc thư rác tiêu chuẩn.
Quy trình 6 thành phần nêu trên là quy trình tiêu chuẩn, tuy nhiên trong thực tế, những bộ lọc thư rác có thể không chỉ bao gồm các thành phần này.
Trong đó, một trong những phương pháp phổ biến từ phía người dùng được Gmail, Yahoo!, Outlook sử dụng là danh sách đen, chặn những địa chỉ hoặc tên miền mà người dùng cho là thư rác. Phương pháp khác cũng được sử dụng rộng rãi là lọc dựa trên quy luật. Trong Gmail, Yahoo! và Outlook, người dùng có thể tạo danh sách trắng (whitelist) cho những người gửi đã biết trước. Ngoài ra, Outlook cho phép người dùng chặn những email có ngôn ngữ lạ thông qua Danh sách mã hóa đã bị chặn (Blocked Encodings List).
Mặc dù các bộ lọc thư rác ngày càng phát triển, nhưng người dùng vẫn có thể bị ngập trong thư rác mỗi ngày, vì kẻ phát tán thư rác có thể nhanh chóng thích ứng các kỹ thuật mới, cũng như do sự thiếu linh hoạt của các bộ lọc thư rác để thích nghi với sự thay đổi.
Nhằm xử lý thư rác một cách hiệu quả, những nhà cung cấp dịch vụ thư điện tử hàng đầu như Gmail, Yahoo!, Outlook đã triển khai kết hợp các kỹ thuật học máy như mạng nơ-ron trong bộ lọc thư. Các kỹ thuật học máy này có thể học và nhận diện thư rác và lừa đảo bằng cách phân tích khối lượng lớn thư trong rất nhiều máy tính. Nhờ vào khả năng thích nghi với các điều kiện khác nhau của học máy, các bộ lọc thư của Gmail và Yahoo! không chỉ phân loại dựa trên quy luật có sẵn, mà còn tự sinh ra luật mới dựa trên những gì đã học được ngay trong quá trình hoạt động. Mô hình học máy của Google hiện tại có thể phát hiện thư rác và thư lừa đảo với độ chính xác lên tới 99,9%. Trong đó, 91,7% là phân loại sử dụng thuật toán học máy tuyến tính, 4,7% sử dụng đánh giá uy tín, 3,5% sử dụng học sâu và 0,1% sử dụng Tensorflow.
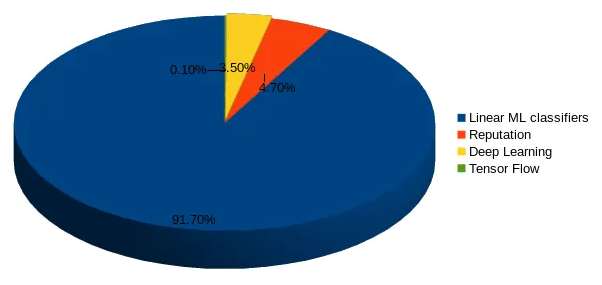
Hình 3. Tỉ lệ các kỹ thuật học máy mà Google sử dụng để lọc thư rác
Trước khi đi thẳng tới các kỹ thuật học máy, thì cần nắm rõ tầm quan trọng của tập dữ liệu và các loại tập dữ liệu có thể có để huấn luyện bộ lọc thư rác. Theo sách Data Cleaning (2019) của hai tác giả Ihab F. Ilyas và Xu Chu: “Chất lượng dữ liệu là một trong những vấn đề quan trọng nhất trong quản lý dữ liệu, vì dữ liệu không sạch thường dẫn đến kết quả phân tích dữ liệu và các quyết định công việc không chính xác”. Một số tập dữ liệu cho bộ lọc thư rác phổ biến được sử dụng trong huấn luyện và đánh giá như [1]:
- Spambase: Tập dữ liệu của Đại học California (Mỹ) rất phổ biến để huấn luyện bộ lọc thư rác, chứa 4.601 thư điện tử và 48 đặc tính (feature), thu thập từ quản trị viên của máy chủ thư điện tử và cá nhân có tệp thư rác;
- SMS Spam: Một tập dữ liệu khác của Đại học California, cũng là bộ dữ liệu thường dùng để huấn luyện học máy khác, thích hợp để phân loại tin nhắn điện thoại, không phải trực tiếp của thư điện tử;
- Spam Assassin: Ưu điểm chính của tập dữ liệu này là chia tập dữ liệu thành thư rác và không phải thư rác dựa trên độ phức tạp của nó;
- Spam Data: Tập dữ liệu chứa 9.324 thư điện tử, thu thập từ các bài đăng trên Usenet (hệ thống mạng phân tán toàn cầu dành cho người dùng Unix, dưới dạng diễn đàn thảo luận) trong bộ sưu tập 20 Newsgroup và từ nhiều tài khoản thư điện tử của các máy chủ thư điện tử khác nhau.
Dựa trên khảo sát [2], phần lớn các mô hình lọc thư rác có ứng dụng học máy sử dụng 2 kỹ thuật phổ biến là sử dụng thuật toán Naïve Bayes và SVM, ngoài ra còn sử dụng học sâu bao gồm các mạng nơ-ron.
Sử dụng thuật toán Naïve Bayes
Theo thuật toán Naïve Bayes, để quyết định thư E có phải là thư rác (Spam) hay thư bình thường (Ham), có thể thông qua so sánh 2 xác suất có điều kiện: P[spam|X] và P[ham|X] (X là tập các đặc tính của thư E).
Công thức Bayes được sử dụng để tính xác suất thư rác với giả định rằng tất cả các đặc tính trong thư là độc lập, không phụ thuộc lẫn nhau. Ví dụ, trong email X có xuất hiện các từ “sold”, “selloff”, “price”, “free”, “apply”, “exclusive”, “deal”, “click”, “now”, ... Mỗi từ có thể được coi là một đặc tính, với giả định rằng tất cả các từ là độc lập. Nhưng thực tế thì không phải vậy, vì “exclusive” thường đi với “deal” và “click” thường theo sau bởi “now”, ... Do dựa vào giả định là “Naïve” (ngây thơ) như vậy, nên thuật toán có tên là Naïve Bayes. Tuy nhiên, giả định này lại mang tới một kết quả bất ngờ về cả độ chính xác lẫn tốc độ trong huấn luyện và dự đoán, phù hợp cho tập dữ liệu lớn, nhiều chiều và chống nhiễu.
Quá trình xây dựng bộ lọc sử dụng Naïve Bayes gồm 3 giai đoạn [3]:
1. Tiền xử lý dữ liệu (pre-processing): Dữ liệu thô thường không đầy đủ, chứa giá trị nhiễu. Giai đoạn này loại bỏ nhiều từ thừa như các từ liên kết hoặc những đoạn không cần thiết cho quá trình phân loại;
2. Lựa chọn đặc tính (feature selection): Như trong ví dụ nêu trên, một từ trong thư có thể được coi là một đặc tính. Tuy nhiên, để huấn luyện mô hình thì đặc tính cần chuyển thành số liệu. Do đó, đặc tính có thể là xác suất xuất hiện của từ đó trong thư điện tử, số lượng sai chính tả, ... Những đặc tính này có thể được chọn lựa thủ công hoặc thông qua một số phương pháp tính toán;
3. Áp dụng thuật toán Naïve Bayes để thu được kết quả phân loại [4].
Việc đánh giá thuật toán này được trích dẫn từ kết quả từ nghiên cứu [3]. Các tác giả sử dụng 2 tập dữ liệu là Spam Data và Spambase (như đã mô tả ở trên) và đánh giá độ chính xác của thuật toán khi sử dụng chúng (Hình 4).
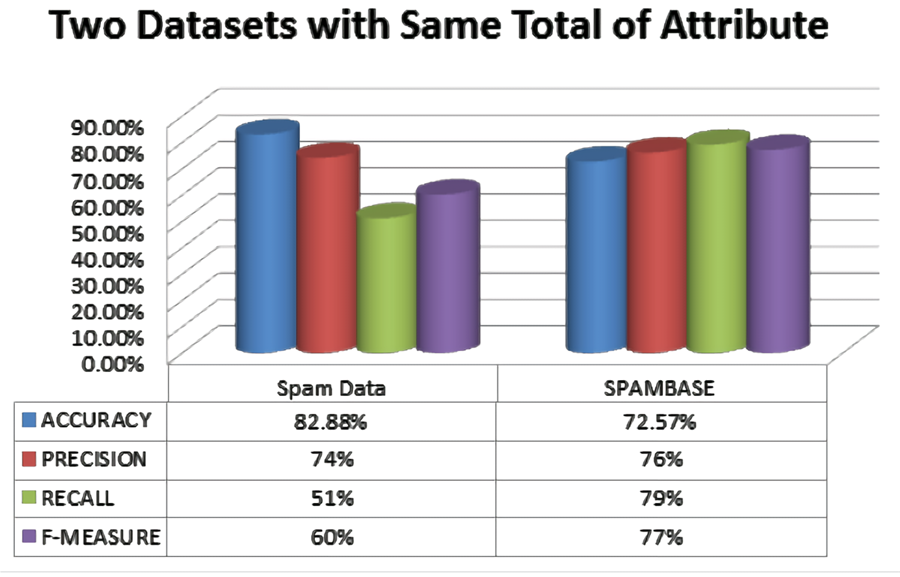
Hình 4. Đánh giá bộ thư rác sử dụng Naïve Bayes với tập dữ liệu Spam Data và Spambase.
Trong đó:
- Accuracy: Phần trăm xác định đúng thư rác và thư bình thường;
- Recall: Phần trăm thư rác được chặn đúng;
- Precision: Tỷ lệ dự đoán thư rác đúng;
- F-Measure: Trung bình của Accuracy và Recall có trọng số.
Từ kết quả thu được, nhóm tác giả nhận định rằng, bộ lọc sử dụng Naïve Bayes có hiệu suất tốt hơn trên tập Spambase so với tập Spam Data, ngay cả khi Spam Data đạt được chỉ số Accuracy cao hơn. Do bộ lọc có kết quả tốt trên Precision, Recall và F-measure cũng quan trọng không kém. Spam Data có nhiều đặc tính và mẫu của thư với tổng cộng 9.324 thư và 500 đặc tính, thu thập từ rất nhiều tài khoản thư điện tử khác nhau, trong khi Spambase có 4.601 thư và 58 đặc tính với dữ liệu chỉ từ một tài khoản.
Có sự khác biệt về kết quả như vậy là do bộ lọc sử dụng Naïve Bayes không nhất định cần nhiều số lượng mẫu thư và đặc tính lớn để huấn luyện phân loại cho bộ lọc thư rác.
Thuật toán phân loại sử dụng Naïve Bayes có thể thực hiện tốt hơn trên tập dữ liệu thu thập từ một tài khoản thư điện tử so với nhiều tài khoản. Đó là bởi bộ lọc Naïve Bayes có thể tập trung huấn luyện với nhiều loại thư rác khác nhau đến từ riêng một tài khoản.
Với những khả năng này, người dùng có thể tự cài đặt bộ lọc trên thiết bị một cách độc lập, và tiếp tục huấn luyện với dữ liệu riêng để có được bộ lọc hiệu quả hơn, phù hợp với tài khoản thư điện tử của mình.
Các bộ lọc trên máy chủ như DSPAM, SpamAssassin, SpamBayes, Bogofilter và ASSP đều sử dụng thuật toán Naïve Bayes và nó có thể được nhúng vào hệ thống của các nhà cung cấp dịch vụ thư điện tử.
Tuy nhiên, bộ lọc sử dụng Naïve Bayes có thể bị phá vỡ bởi kẻ phát tán thư rác bằng cách thêm nhiều từ hợp lệ trong thư rác, dẫn đến bộ lọc có thể phân loại nhầm. Tuy nhiên, vấn đề này có thể được giải quyết bằng biểu đồ Paul Graham - chỉ sử dụng những đặc tính cần thiết, tập trung vào những từ quan trọng trong việc phân loại thư.
Một tình huống khác là kẻ phát tán thư rác có thể thay thế từ ngữ bằng hình ảnh để vượt qua bộ lọc Naïve Bayes, do vậy cần tích hợp các phương pháp khác theo để giải quyết.
Sử dụng thuật toán SVM Support
Vector Machine (SVM) là thuật toán được chứng minh có hiệu suất rất tốt trong bài toán phân loại văn bản.
Mục tiêu của SVM là tìm một ranh giới quyết định nhằm chia 2 nhóm dữ liệu, đồng thời tối đa khoảng cách lề (margin). Khoảng cách lề là khoảng cách giữa đường ranh giới và điểm dữ liệu gần nhất của 2 nhóm, điểm dữ liệu cũng được gọi và vector, và trong bài toán thư rác thì một vector có thể biểu diễn một thư điện tử. Khoảng cách lề càng lớn thì 2 nhóm càng được phân chia rõ ràng.
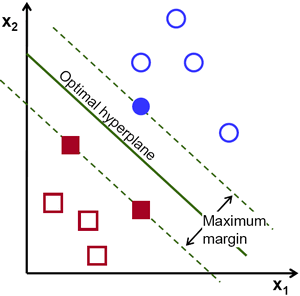
Hình 5. Trường hợp có thể phân chia tuyến tính sử dụng thuật toán SVM
Trong trường hợp không thể phân chia tuyến tính (như Input Space trong Hình 6), SVM sử dụng 2 ý tưởng:
- Khoảng cách lề không thẳng (soft margin): SVM vẫn tìm một “đường thẳng” (chính xác là siêu phẳng) nhưng bỏ qua một số điểm dữ liệu phân loại sai nhằm tìm ra một “đường thẳng” chấp nhận được; - Kỹ thuật hạt nhân (kernel trick): sử dụng các đặc tính đã có, áp dụng các hàm biến đổi để tạo ra các đặc tính mới (tức chuyển đổi, ánh xạ từ không gian dữ liệu ban đầu sang không gian có nhiều chiều hơn) nhằm tìm ra một “đường thẳng” phân cách trong không gian mới.
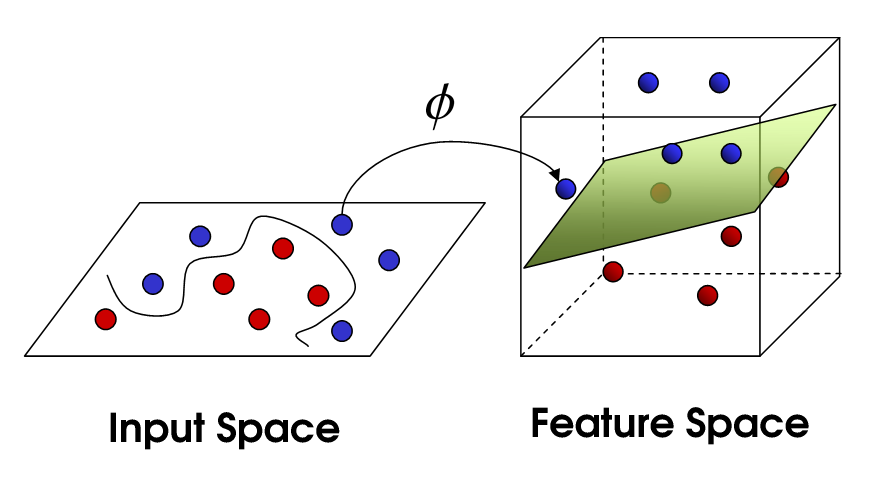
Hình 6. Trong trường hợp không thể phân chia tuyến tính trong SVM
Quy trình và phương pháp đánh giá việc áp dụng thuật toán SVM cơ bản giống như thuật toán Naïve Bayes. Phần đánh giá có được trong Bảng 1 [5]:
Bảng 1. Đánh giá bộ lọc thư rác áp dụng thuật toán SVM
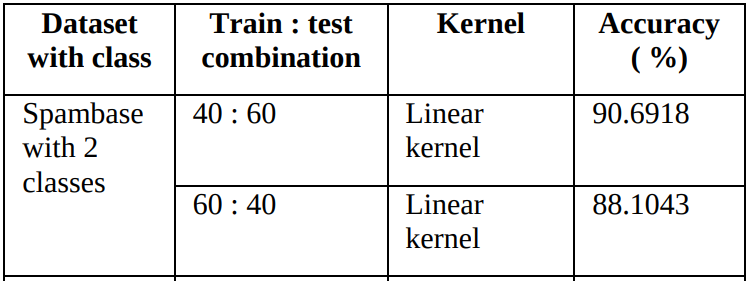
Có rất nhiều biến thể của SVM để đạt được kết quả tốt hơn như trong [6]. Kết quả này còn tốt hơn so với Naïve Bayes với tập dữ liệu Spambase. Tuy nhiên, SVM thường yêu cầu thời gian huấn luyện là hàm bậc hai của số lượng mẫu huấn luyện, không thực tế với hệ thống thư điện tử. Trong khi đó, Naïve Bayes chỉ yêu cầu thời gian tính toán là hàm tuyến tính, dễ dàng triển khai trực tuyến và cập nhật. Điều này cho phép hệ thống sử dụng Naïve Bayes có thể dễ dàng thích nghi với sự thay đổi giữa các môi trường.
Như đã đề cập ở trên, người gửi thư rác có thể thay đổi văn bản bằng hình ảnh, và SVM có thể xử lý vấn đề này. Tương tự như phân loại văn bản, nhưng SVM sử dụng đặc tính của hình ảnh như: siêu dữ liệu (kích cỡ, tỷ lệ khung hình, tỷ lệ nén, độ sâu bit), màu sắc, kết cấu, hình dáng, nhiễu, ...
Nhóm tác giả trong [7] sử dụng 2 tập dữ liệu có sẵn với 38 đặc tính, cụ thể: Tập dữ liệu ISH và Dredze, kèm với một tập dữ liệu khó hơn do nhóm tác giả tự tạo, đạt được kết quả như Hình 7, trong đó False Positive rate - FPR: trong đó tỷ lệ thư bình thường bị phân loại nhầm thành thư rác.
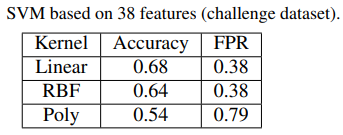
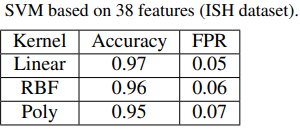
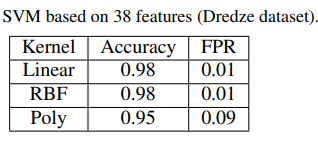
Hình 7. Đánh giá bộ lọc thư rác áp dụng thuật toán SVM với 3 tập dữ liệu khác nhau
Kết quả cho thấy, SVM có thể hoạt động tốt trên tập dữ liệu ISH và Dredze nhưng không tốt trên tập phức tạp hơn. Do đó, cần có một bộ lọc hình ảnh tốt hơn (như mạng nơ-ron).
Sử dụng mạng nơ-ron
Ajay Pal Singh đã đề xuất một dự án sử dụng nhiều mạng nơ-ron trong [8]. Mạng nơ-ron đầu tiên là một mạng nơ-ron truyền ngược (back-propagation) bao gồm một lớp ẩn với 20 nơ-ron. Lớp đầu vào là dữ liệu với 38 đặc tính như phần trên. Mô hình cho kết quả tốt hơn với 2 tập dữ liệu ISH và Dredze. Mạng nơ-ron thứ hai là 3 mạng CNN, bao gồm CNN1, CNN2 và huấn luyện chuyển giao (transfer learning) với mô hình đã huấn luyện trước là VGG19.
Dữ liệu huấn luyện cho cả 3 mô hình là tổng hợp của 3 tập dữ liệu đã đề cập. Trong đó, mô hình sử dụng trọng số của VGG19 kháng nhiễu tốt hơn đối với hình ảnh (trong tập dữ liệu phức tạp hơn) với 390/1.029 hình ảnh phân loại đúng. Mặc dù kết quả này thấp hơn so với SVM đối với tập dữ liệu phức tạp, nhưng đây vẫn là một gợi ý về cách tiếp cận mới đối với học sâu trong lĩnh vực lọc thư rác.


Hình 8. Đánh giá bộ lọc thư rác sử dụng mạng nơ-ron
Lọc thư rác sử dụng thuật toán Naïve Bayes đơn giản, dễ huấn luyện và triển khai, phù hợp cho cả bộ lọc cá nhân và máy chủ, do vậy nó được sử dụng rộng rãi ngày nay. Tuy nhiên, độ chính xác không quá cao và thiếu khả năng xử lý hình ảnh. Sử dụng thuật toán SVM có độ chính xác tốt hơn, cũng như xử lý hình ảnh, nhưng chi phí tính toán lớn hơn so với Naïve Bases. Trong tương lai sẽ có nhiều cải tiến trong cả 2 kỹ thuật trên, thậm chí có thể được kết hợp với các thuật toán khác như KNN, Decision tree,... để có được hiệu suất tốt hơn.
|
TÀI LIỆU THAM KHẢO 1. Baeldung (2020). Publicly Available Spam Filter Training Sets. [online] Available at: https://www.baeldung.com/cs/spam-filter-training-sets [Accessed 10/10/2020]. 2. Hanif B, Akm A, Tamanna I.J et al (2018) A Survey of Existing E-Mail Spam Filtering Methods Considering Machine Learning Techniques. 3. Nurul F.R, Norfaradilla W, Shahreen K et al (2017). Analysis of Naı̈ve Bayes Algorithm for Email Spam Filtering across Multiple Datasets. 4. Pavel H (2020). How to build and apply Naïve Bayes classification for spam filtering. [online] Available at: https://towardsdatascience.com/how-to-build-and-applyNaïve-bayes-classification-for-spam-filtering-2b8d3308501 [Accessed 10/10/2020]. 5. Deepak K.A, Rahul K(2016). Spam Filtering using SVM with different Kernel Functions. 6. Karthika R.D, Visalakshi P (2015). A Hybrid ACO Based Feature Selection Method for Email Spam Classification. 7. Aneri C, Katerina P, Fabio D.T et al (2018). Support Vector Machines for Image Spam Analysis. 8. Ajay P.S (2018). Image Spam Classification using Deep Learning. |
Quang Minh

10:00 | 15/09/2023

16:00 | 24/09/2018

11:00 | 09/04/2021

13:00 | 05/09/2022

16:00 | 22/10/2021

10:00 | 28/03/2024
Google Drive là một trong những nền tảng lưu trữ đám mây được sử dụng nhiều nhất hiện nay, cùng với một số dịch vụ khác như Microsoft OneDrive và Dropbox. Tuy nhiên, chính sự phổ biến này là mục tiêu để những kẻ tấn công tìm cách khai thác bởi mục tiêu ảnh hưởng lớn đến nhiều đối tượng. Bài báo này sẽ cung cấp những giải pháp cần thiết nhằm tăng cường bảo mật khi lưu trữ tệp trên Google Drive để bảo vệ an toàn dữ liệu của người dùng trước các mối đe dọa truy cập trái phép và những rủi ro tiềm ẩn khác.

10:00 | 31/01/2024
Các nhà nghiên cứu tại hãng bảo mật Kaspersky đã phát triển một kỹ thuật mới có tên là iShutdown để có thể phát hiện và xác định các dấu hiệu của một số phần mềm gián điệp trên thiết bị iOS, bao gồm các mối đe dọa tinh vi như Pegasus, Reign và Predator. Bài viết sẽ cùng khám phát kỹ thuật iShutdown dựa trên báo cáo của Kaspersky.

10:00 | 22/09/2023
Internet robot hay bot là các ứng dụng phần mềm thực hiện các tác vụ lặp đi lặp lại một cách tự động qua mạng. Chúng có thể hữu ích để cung cấp các dịch vụ như công cụ tìm kiếm, trợ lý kỹ thuật số và chatbot. Tuy nhiên, không phải tất cả các bot đều hữu ích. Một số bot độc hại và có thể gây ra rủi ro về bảo mật và quyền riêng tư bằng cách tấn công các trang web, ứng dụng dành cho thiết bị di động và API. Bài báo này sẽ đưa ra một số thống kê đáng báo động về sự gia tăng của bot độc hại trên môi trường Internet, từ đó đưa ra một số kỹ thuật ngăn chặn mà các tổ chức/doanh nghiệp (TC/DN) có thể tham khảo để đối phó với lưu lượng bot độc hại.

14:00 | 14/09/2023
NFT (Non-fungible token) là một sản phẩm của thời đại công nghệ mới và đang phát triển như vũ bão, ảnh hưởng sâu rộng đến nhiều lĩnh vực. Thị trường NFT bùng nổ mạnh mẽ vào năm 2021, tăng lên khoảng 22 tỷ USD và thu hút ước tính khoảng 280 nghìn người tham gia. Nhưng khi thị trường này phát triển, phạm vi hoạt động của tin tặc cũng tăng theo, đã ngày càng xuất hiện nhiều hơn các báo cáo về những vụ việc lừa đảo, giả mạo, gian lận và rửa tiền trong NFT. Bài báo sau sẽ giới thiệu đến độc giả tổng quan về NFT, các hành vi lừa đảo NFT và cách thức phòng tránh mối đe dọa này.
08:00 | 11/01/2024 | Chính sách - Chiến lược

09:00 | 10/01/2024 | Giải pháp khác

09:00 | 05/01/2024|Chính sách - Chiến lược
09:00 | 05/01/2024|An ninh – Quốc Phòng

Lược đồ chữ ký số dựa trên hàm băm là một trong những lược đồ chữ ký số kháng lượng tử đã được Viện Tiêu chuẩn và Công nghệ Quốc gia Mỹ (NIST) chuẩn hóa trong tiêu chuẩn đề cử FIPS 205 (Stateless Hash Based Digital Signature Standard) vào tháng 8/2023. Bài báo này sẽ trình bày tổng quan về sự phát triển của của lược đồ chữ ký số dựa trên hàm băm thông qua việc phân tích đặc trưng của các phiên bản điển hình của dòng lược đồ chữ ký số này.
09:00 | 01/04/2024

Mới đây, Cơ quan An ninh mạng và Cơ sở hạ tầng Hoa Kỳ (CISA) đã phát hành phiên bản mới của hệ thống Malware Next-Gen có khả năng tự động phân tích các tệp độc hại tiềm ẩn, địa chỉ URL đáng ngờ và truy tìm mối đe dọa an ninh mạng. Phiên bản mới này cho phép người dùng gửi các mẫu phần mềm độc hại để CISA phân tích.
13:00 | 17/04/2024


















